So I routinely run two of the same spool type for large jobs over 1kg, this creates a problem: sometimes the AMS switchover results in a cooling and shrinking, but the most common issue is the flow calibration for the initial spool can be too different from the k value for the 2nd spool.
How do I know? after running several dozen of the same job, which requires two spools each, if I use default values and disable flow dynamics calibration (pressure advance) or if I let it calibrate the first one, the layers printed with the second spool results in a different look to it’s corners. Trust I ran the gamut of checks on FIVE X1Cs, adjusting belts, lube, squareness, etc. what fixed it was flow dynamics calibration - but for each spool before printing.
This is now part of my workflow, and though it takes about 15 minutes, it’s a welcome assuredness I have come to embrace.
What I’m having trouble with though is two things:
I would love to be able to run Flow Dynamics (Pressure Advance) Calibration from the printer and store it to a spool setting on the AMS not just on the first spool at the beginning of a job, but manually on some or all spools in the AMS and have it store the values to the AMS settings - like Bambu Studio can in it’s Calibration Page. I can imagine a menu function to perform this but it’s likely a bridge too far for the firmware to handle this.
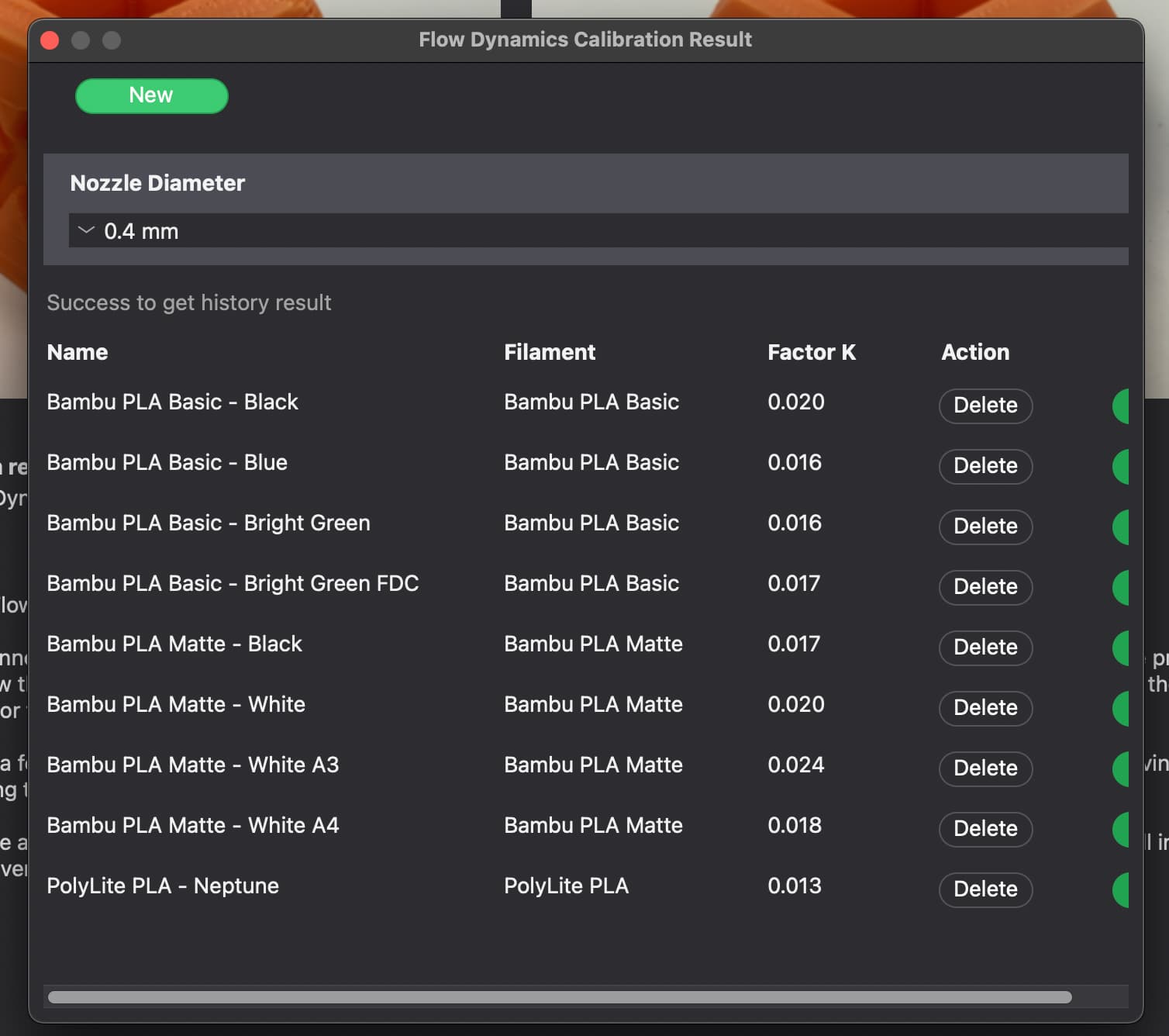
Keeping track of K-value results is getting disorganized. I have to occasionally go into the calibration page, Manage Result, and delete the duplicates I named differently. It’s left me having to name them like “Bambu PLA Matte - White X1C1 A1 7-31” “…A2…” etc. it gets exhausting, but is the only way to keep track of spools each time I print. I’ve considered labeling the profile by the K-Value in the hopes of making essentially a static library per printer I can re-use, but then I need to label the spools physically as well, e.g. dry erase marker or print labels on my thermal printer - this might be a future method of keeping this organized, and maybe running it once per spool when I finish drying them. Problem is I’m lazy and this is a lot of extra work lol.
Pie in the Sky: If somehow the Bambu’s RFID tags, if they have a truly unique identifier (serial number) it would be so rad if the AMS could simply reference that and match the calibrated value, it won’t happen anytime soon, but would be pretty sweet.
Anyone else have this meticulous of a workflow? I’m printing aesthetic prints that require perfection for the price points I sell them at.
Here’s an image to show an extreme of what can happen when the K-value is drastically different from one spool to another of the same filament:
I don’t focus primarily on aesthetics, but on achieving dimensional tolerances with the best surface finish possible. That said, I agree that flow dynamics calibration (i.e. Pressure Advance) and flow rate are essential, and I also run it for every single spool, regardless of brand consistency.
I skip the auto-calibration at the start of a print and instead perform pressure advance and flow rate calibrations per spool in advance. I then store those values manually under uniquely named profiles. I’ve learned that the pressure advance (K-value) can vary significantly — particularly between batches or after drying- even within the same filament type, brand, and colour.
To manage this, I do the following:
Maintain labelled profiles in Bambu Studio with tags like “PLA Basic - White v1”, “v2”, etc., even if the official name and colour are identical.
Use a label maker to tag physical spools accordingly so I can match them with their calibration profiles.
Run short test prints using both spools before starting any job requiring a switchover — this helps confirm calibration accuracy and detects issues like moisture in advance.
I also back up the calibration database regularly. I’m refining an OCR-based script to extract K-values from Bambu Studio screenshots for archival purposes. Still, I also access the remaining data directly via the filament .json profiles, which makes batch parsing and backup easier.
Someone posted a “would anyone be interested in this” in the orcaslicer discussions, no one replied so I’m guessing that is why the author didn’t submit a pull request for it.
Bambu’s RFID tags include the spool’s production date (so they can match it to batches, I assume), but the tags do not uniquely identify each spool with a unique serial number or ID.
EDIT: I did not read closely enough. The tag’s unique ID is used as the spool’s unique ID.
Details, if you’re curious:
While it’s not automated the way you are looking for, 3Dfilamentprofiles.com does let you generate unique QR codes for each of your own spools. It might make some of your housekeeping easier. (Unfortunately it doesn’t track per-spool K-values.) https://3dfilamentprofiles.com/
I read them both, but I read them wrongly. No need to be snotty and condescending about it.
(I focused on the BRG analysis, which includes production date/time in Blocks 12-13, key temperature and related data in Blocks 2-8 and 10. Anyway, I was wrong, I’ll edit my previous most so I don’t mess up people who find this in the future.)